이미지에서 웹 엔티티, 동일 이미지, 부분 매칭, 유사 이미지, 출처 페이지 후보를 반환합니다. 외부 ML 서비스가 만든 탐지 결과입니다.
AI/ML usage explainer
Copyrighter의 AI/ML은 판정 자동화가 아니라 근거 자동화입니다.
시스템은 제출 이미지를 분석해 유사 이미지, 웹 출처, 인물 존재 신호, 기준 DB 유사도, 검색 증거, LLM 요약을 만듭니다. 최종 저작권 위험 판정은 운영자가 하며, AI/ML 출력은 그 판단을 빠르게 만드는 검토 근거입니다.
AI/ML 사용이라고 말할 수 있다.
컴퓨터 비전 ML, 로컬 생성형 AI, 얼굴/인물 감지, 이미지 유사도 계산이 실제 처리 흐름에 포함되어 있습니다.
정확한 표현
“AI가 침해 여부를 확정한다”가 아니라 “AI/ML이 출처 기반 증거와 위험 triage를 생성하고, 운영자가 최종 판단한다”입니다.
Definitions
이 문서에서 AI, ML, 알고리즘은 서로 다른 역할을 합니다.
혼동을 줄이려면 “어떤 기술이 무엇을 보고, 무엇을 산출하며, 그 산출물이 점수에 어떻게 반영되는지”를 분리해야 합니다.
저장된 evidence만 입력으로 받아 운영자용 요약을 생성합니다. 새 사실을 만들거나 최종 판정을 내리지 않도록 제한합니다.
OpenCV Haar cascade로 얼굴 박스 존재를 탐지합니다. 동일인 식별, 얼굴 임베딩, 신원 추정은 수행하지 않습니다.
학습 모델은 아니지만 이미지 내용의 지문을 만들고 해밍 거리로 유사도를 계산해 기준 DB 및 검색 결과 이미지와 비교합니다.
Operating pipeline
한 장의 제출 이미지는 evidence 묶음으로 변환됩니다.
위험 점수는 LLM이 직접 만든 값이 아니라, 각 evidence의 유형과 신뢰도에 규칙을 적용해 계산한 triage 점수입니다.
flowchart LR A[제출 이미지] --> B[로컬 전처리] B --> C[SHA / pHash 지문 생성] B --> D[얼굴·인물 존재 감지] B --> E[Google Vision Web Detection] E --> F[웹 엔티티·동일 이미지·부분 매칭·출처 페이지] F --> G[Naver 텍스트 검색 보강] F --> H[레거시 Google 맞춤 검색
비활성 가능] C --> I[기준 DB 및 검색 결과 이미지 유사도 비교] D --> J[로컬 인물 존재 evidence] F --> K[Google evidence] G --> L[Naver evidence] H --> L I --> M[유사도 evidence] J --> N[규칙 기반 위험 점수] K --> N L --> N M --> N K --> O[Ollama LLM 요약] L --> O M --> O O --> P[출처 연결 요약 evidence] N --> Q[운영자 검토] P --> Q Q --> R[승인 / 보류 / 반려] classDef ai fill:#edf7fb,stroke:#24667a,color:#172124; classDef cv fill:#ecf8f1,stroke:#28734f,color:#172124; classDef rule fill:#fff7e2,stroke:#916300,color:#172124; classDef human fill:#fff0ed,stroke:#a13d35,color:#172124; class E,O ai; class C,D,I cv; class N rule; class Q,R human;
What comes out
각 기술은 서로 다른 결과물을 만들고, UI는 이를 한 줄의 판단 근거로 모읍니다.
이 구분이 중요합니다. “신뢰도”는 하나의 전역 AI 확률값이 아니라 evidence별 confidence, 유사도, 매칭 유형, 규칙 점수의 조합입니다.
Google Vision
웹 엔티티, full/partial/visual image match, matching page, weak label을 생성합니다.
confidence는 Google score 또는 fallback confidence에서 옵니다.
Naver 검색
Google/기준 DB에서 나온 이름, 페이지 제목, 라벨을 텍스트 쿼리로 확장해 블로그/웹문서 근거를 모읍니다.
promoted 결과만 위험 점수에 직접 기여합니다.
pHash 유사도
64비트 perceptual hash의 해밍 거리로 0.0~1.0 유사도를 계산합니다.
0.9 이상이면 강한 동일/유사 이미지 신호로 취급합니다.
얼굴/인물 감지
얼굴 또는 인물이 있는지 presence-only 신호를 제공합니다.
신원 식별 confidence가 아니라 위험 검토 필요성 신호입니다.
Ollama LLM 요약
기존 evidence의 출처, 이유, confidence, URL만 보고 내부 운영자용 요약을 생성합니다.
위험 점수에는 직접 가산되지 않습니다.
Score and confidence
위험 점수는 AI의 “확률”이 아니라 규칙 기반 triage 점수입니다.
evidence에는 confidence가 붙지만, 최종 riskScore는 `RiskScorer`가 evidence 유형별 가중치를 더해 0~100으로 제한한 값입니다. 따라서 “100점 = 100% 침해 확률”이 아니라 “검토 우선순위가 매우 높음”입니다.
Band
점수는 운영 큐 정렬을 위한 구간으로 변환됩니다.
- 70점 이상: 높음
- 30점 이상 70점 미만: 중간
- 30점 미만: 낮음
- LLM 요약 evidence는 점수 가산에서 제외됩니다.
| 근거 유형 | 점수 반영 방식 | 의미 |
|---|---|---|
| pHash 유사도 | similarity 0.9 이상이면 +80, 그 외 의미 있는 지문 근거는 +30 | 기준 DB 또는 검색 결과 이미지와 시각적으로 매우 가깝다는 신호 |
| 얼굴/인물 존재 | 존재 신호가 있으면 +35 | 초상권/인물 이미지 검토가 필요할 수 있다는 신호 |
| Google full match | 동일 이미지 매칭은 +45 | 웹에 같은 이미지가 존재한다는 강한 출처 후보 |
| Google partial/page match | 부분 이미지 또는 페이지 매칭은 +35 | 일부 요소 또는 출처 페이지가 제출 이미지와 관련될 가능성 |
| Google visual match | 시각적 유사 이미지는 +10 | 약한 참고 신호이며 단독으로 강한 판정 근거가 되지 않음 |
| Naver promoted 검색 결과 | round(50 * confidence) | 검색 결과가 기준 후보로 승격될 만큼 관련성이 있다고 본 경우 |
| Ollama LLM 요약 | 0점 | 판정 점수가 아니라 사람이 읽기 쉬운 출처 연결 설명 |
Trust boundaries
신뢰도는 단계별로 다르게 해석해야 합니다.
설명 자료에서는 “AI 신뢰도” 하나로 뭉뚱그리지 말고 아래처럼 말하는 편이 정확합니다.
Google score, fallback confidence, 검색 승격 confidence처럼 개별 근거에 붙는 값입니다.
pHash 거리에서 나온 이미지 유사도입니다. ML 확률이 아니라 지문 거리 기반 수치입니다.
여러 근거를 규칙으로 합산한 운영 우선순위 점수입니다. 법적 침해 확률이 아닙니다.
LLM guardrail
LLM은 근거를 요약할 뿐, 새 결론을 만들지 못하게 설계되어 있습니다.
프롬프트는 “제공된 source evidence만 요약하라”, “최종 결정을 내리지 말라”, “근거 없는 주장을 추가하지 말라”로 제한됩니다. 요약 evidence에는 source URL 또는 source evidence id가 연결됩니다.
sequenceDiagram
participant DB as Evidence DB
participant LLM as Ollama 로컬 LLM
participant UI as 운영 콘솔
participant Human as 운영자
DB->>LLM: fingerprint, face, google, naver evidence 전달
LLM->>DB: 출처 연결 요약 evidence 저장
DB->>UI: 원문 evidence + 요약 evidence 표시
Human->>UI: 증거 사용/미사용 선택
Human->>UI: 승인/보류/반려 최종 판정
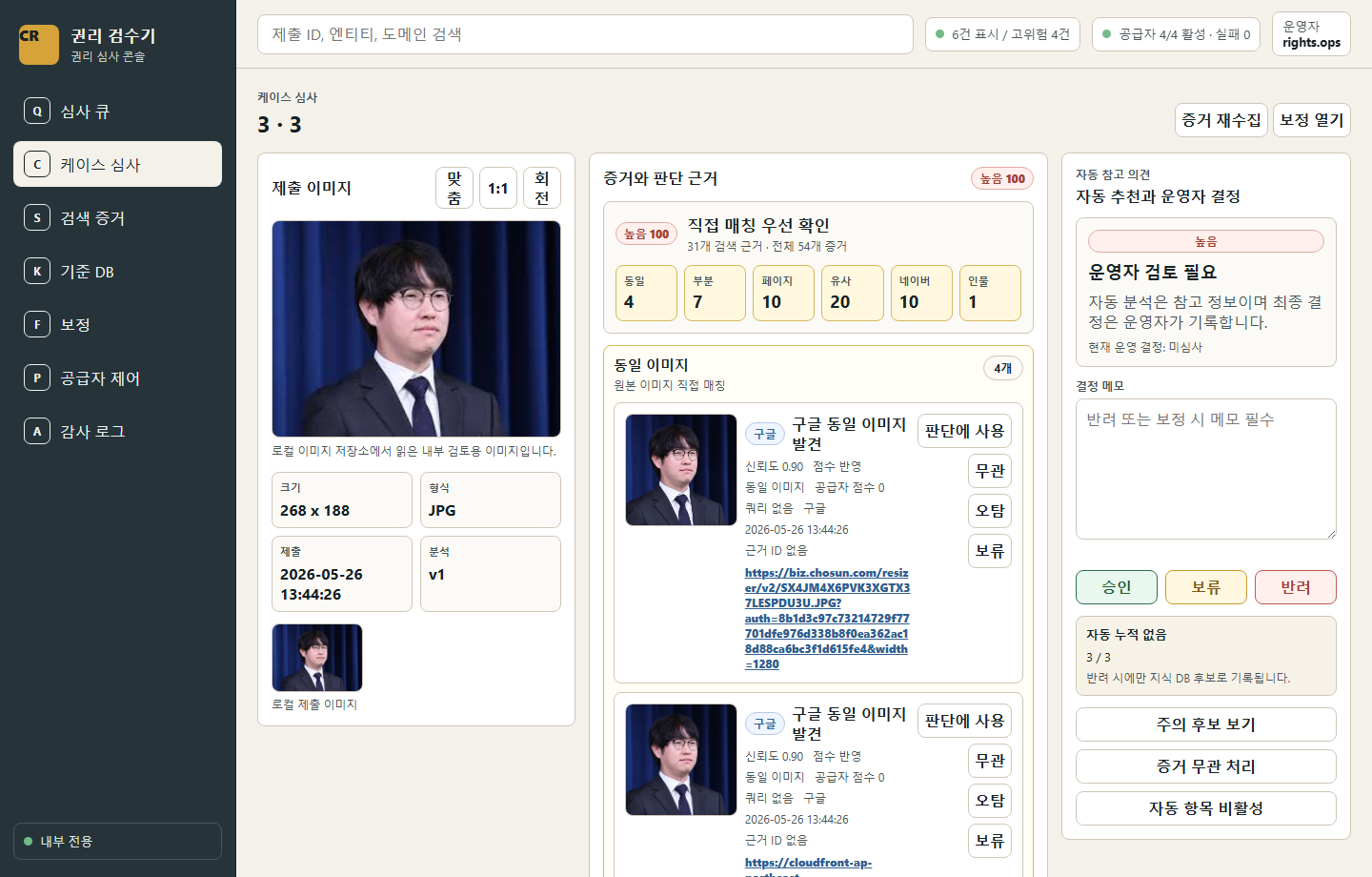
Visual proof
운영 화면은 AI/ML 결과가 어떻게 사람이 검토할 수 있는 근거로 바뀌는지 보여줍니다.
시연에서는 “AI가 판정했다”가 아니라 “AI/ML이 근거를 정리했고 운영자가 판정한다”는 화면 흐름을 보여주는 것이 좋습니다.
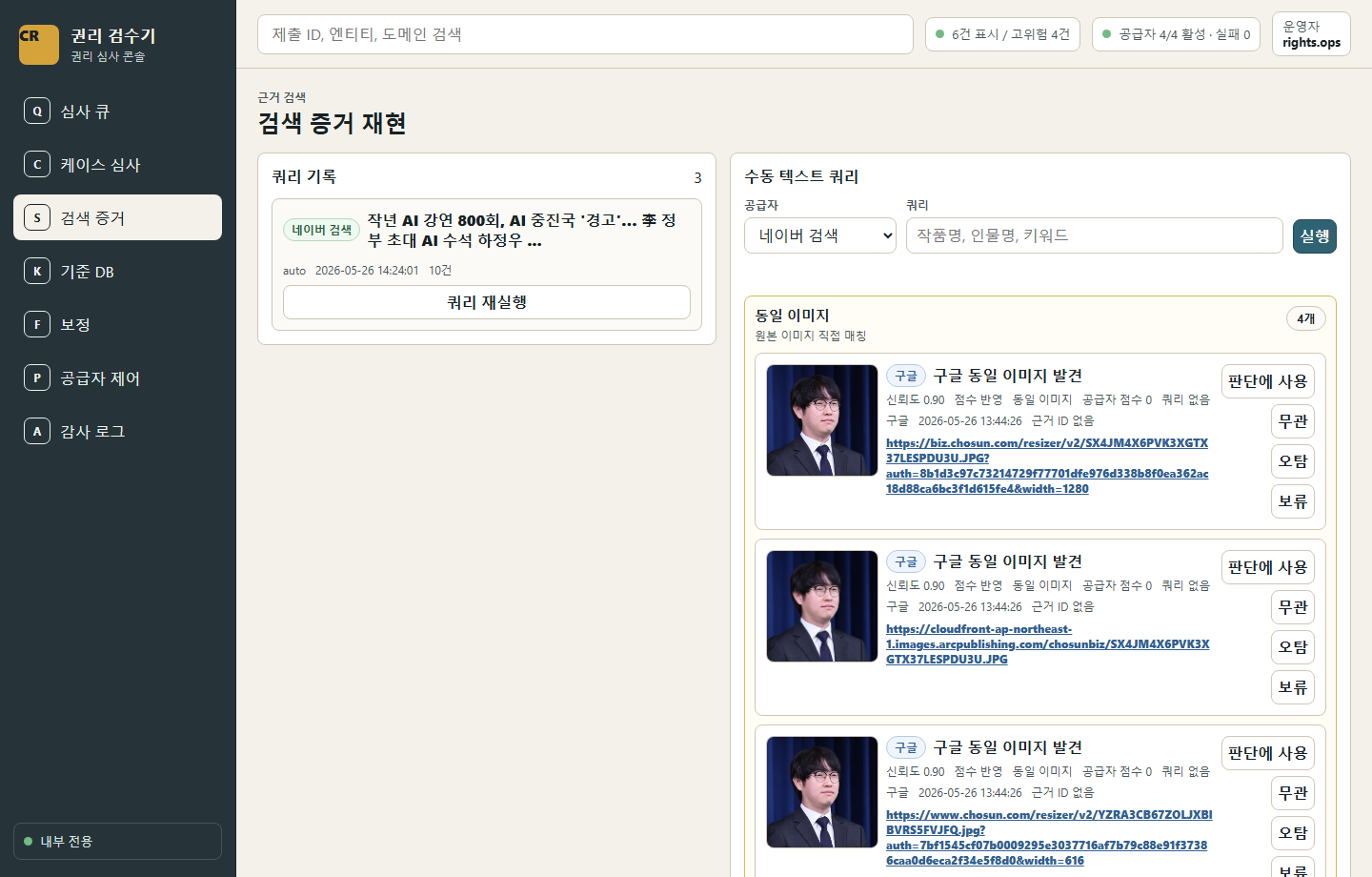
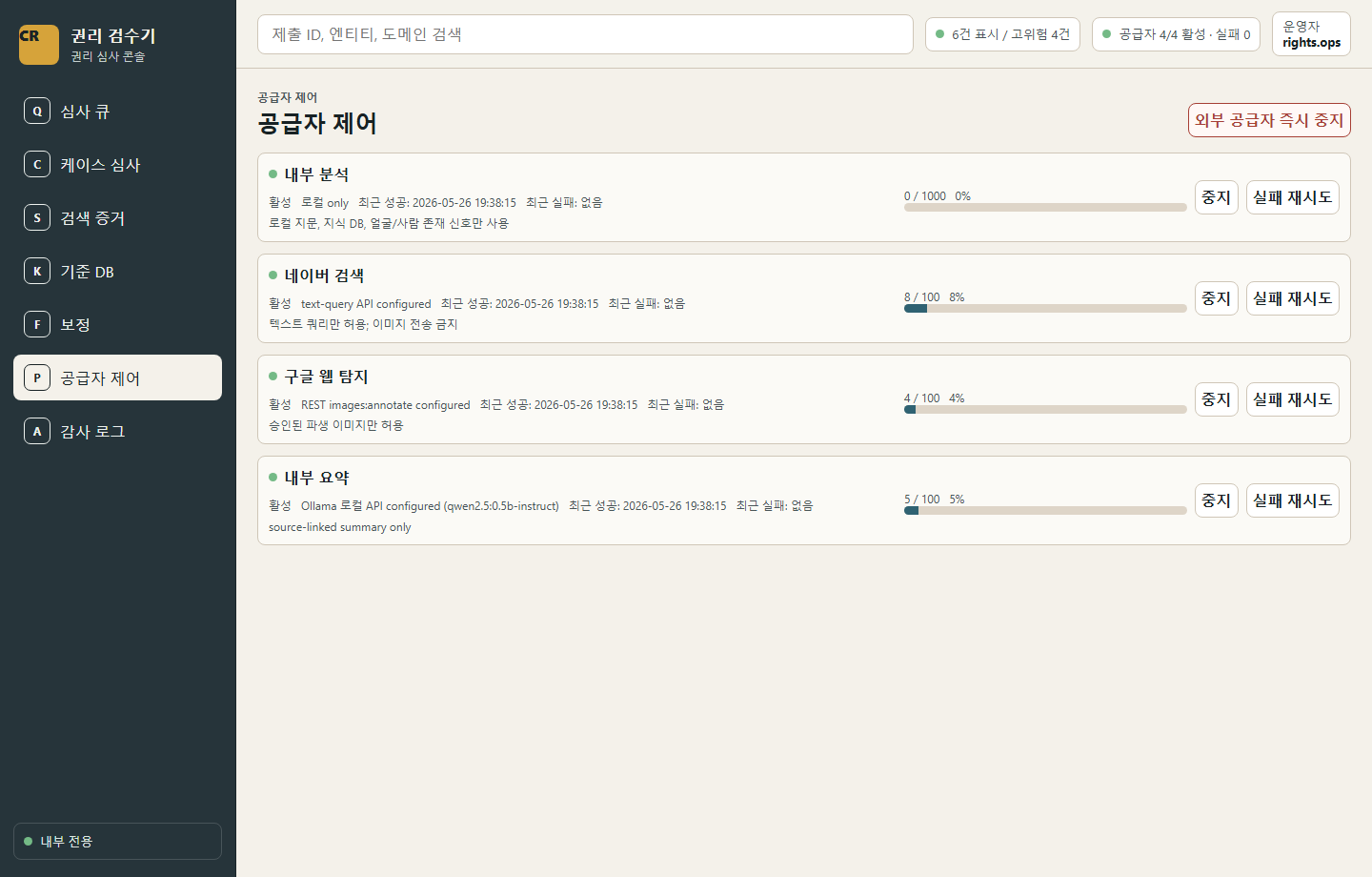
Recommended wording
강조 문구는 기술의 힘과 판정 책임의 경계를 함께 담아야 합니다.
추천 표현
Copyrighter는 컴퓨터 비전 ML, 이미지 지문 유사도, 검색 증거 수집, 로컬 LLM 요약을 결합해 이미지 저작권 위험 검토 근거를 자동 생성합니다.
위험 점수는 AI가 내린 법적 결론이 아니라 evidence confidence, 매칭 유형, 이미지 유사도에 기반한 운영 triage 점수입니다.
최종 승인, 보류, 반려는 운영자가 수행하며 모든 근거는 출처와 함께 보존됩니다.
피해야 할 표현
AI가 저작권 침해 여부를 자동 판정합니다.
LLM이 원작자, 유명인, 침해 여부를 단독으로 확정합니다.
위험 점수 100은 침해 확률 100%를 의미합니다.
Naver에 이미지를 업로드해 역검색합니다.
Code evidence
설명서의 근거가 되는 구현 지점입니다.
- src/rights_filter/integrations/cloud_vision_web_detection.py - Google Cloud Vision Web Detection 호출 및 evidence 매핑
- src/rights_filter/analysis/llm_assistance.py - Ollama Generate API 기반 source-linked LLM 요약
- src/rights_filter/analysis/fingerprints.py - SHA 및 pHash 이미지 지문, 해밍 거리 기반 유사도
- src/rights_filter/analysis/face_person_detection.py - OpenCV Haar cascade 기반 얼굴/인물 존재 감지
- src/rights_filter/analysis/risk_scoring.py - evidence 유형별 규칙 기반 위험 점수 산정
- src/rights_filter/server/sqlite_store.py - evidence 저장, 외부 검색 tool 활용 상태, LLM 요약 자동 생성
- docs/operations/image-rights-risk-filter.md - 외부 API, LLM, 데이터 경계 운영 정책